Chessy - Parte 4
Cuarta parte sobre el mini-proyecto Chessy, aplicación para reproducir partidos de ajedrez. En el post anterior moví un par de cosas a la nube que, aunque simple, funcionaba. Funcionaba hasta que descrubrí que no tanto (!) con archivos mas grandes.
Éste post describe el problema y la solución - junto con otros problemas que aparecieron en el camino.
Archivos grandes
La idea de procesar los archivos PGN1 en lambda fue buena, y funcionó bien para archivos bajados de las webs de los torneos, que tienen un número decente de partidos cada uno. Por ejemplo, el PGN de una edición del Norway Chess pesa 40kb, aproximadamente 45 partidos. Pero uno se emociona (?) y encuentra otros sitios con archivos que traen “todos los partidos de X jugador”. Naturalmente, esos archivos son mas (bastante mas) grandes. Por ejemplo, el de Magnus Carlsen tiene más de 2000 partidos y pesa 2MB.
Con archivos grandes, el parser (en Lambda) falla por “tiempo insuficiente”. El timeout (alrededor de unos 10 segundos) parece no ser suficiente (!). Podría incrementar ese límite (al menos 40x), optimizar el algoritmo, usar otro lenguage… pero el problema de fondo seguiría ahí: la cantidad de trabajo no debería ser tan variable. Así que me pareció mejor limitar la cantidad trabajo asignado al parser: que en lugar de procesar todo un archivo, procese solo una parte.
Así que creé otra función en Lambda, Splitter, que lee el archivo completo (rápidamente), identifica los partidos (comienzo y fin), los agrupa, y los postea como mensajes a una cola (AWS SQS)2. Una segunda función, llamado ParserPartial, lee esos mensajes y parsea igual que ántes, pero solo la parte correspondiente. Y eso es todo!
El esquema cambió de ésto:
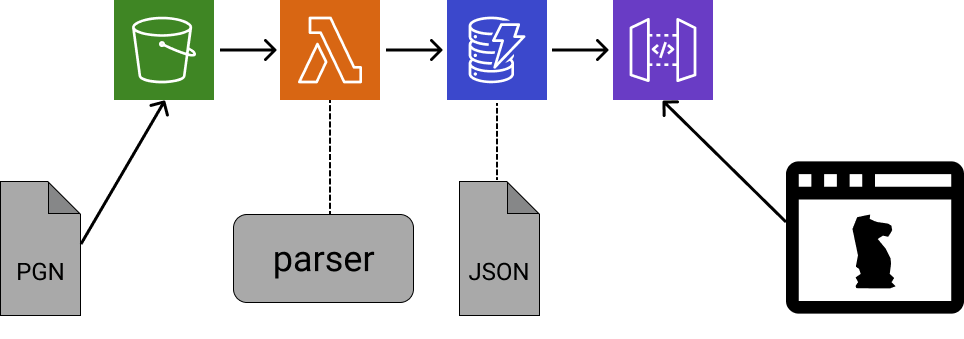
A ésto:
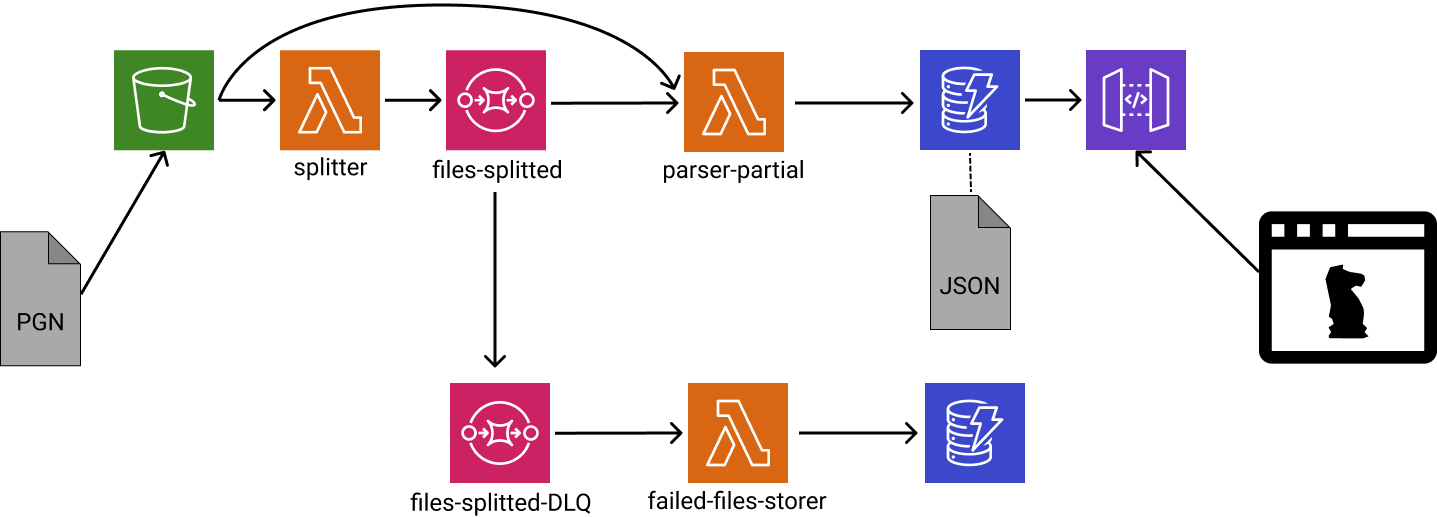
El nuevo esquema garantiza que el parser (ex bottleneck) ahora procese una cantidad de partidos predecible. El nuevo bottleneck pasa a ser Splitter, pero no creo que falle pronto (jaja, ahora seguro lo haces) porque su trabajo es relativamente simple (muchísimo mas simple que el del parser) y vino funcionando con todo lo que probé… De todas maneras, podría usar una estrategia similar si esto se transforma en un problema.
Otros detalles
Una vez resuelto el problema principal, quedaron otros detalles que pulir: ciclos semi-infinitos, la capacidad de escritura de la base de datos y tests.
Ciclos infinitos
Enseguida observé que si un mensaje tomado de la cola no llega a ser procesado (parser error, por ej), vuelve a la cola como dice la especificación. Pero esto hace que otro lambda lo intente procesar mas tarde, falle nuevamente, y el mensaje entre oootra vez a la cola, generando un ciclo semi-infinito (“semi” porque eventualmente es descartado). En mi caso, ésta situación es muy probable porque el parser no es capaz de procesar el 100% de los partidos aún. El problema de fondo está en el parser, pero para arreglarlo necesito tener una lista de partidos problemáticos. Así que debería registrarlos a medida que los encuentre. Por suerte SQS soporta Dead Letter Queue (DQL), que en realidad es otra cola a donde van los mensajes que no se pudieron procesar. Así que me tocó configurar ésto (facilísimo la verdad), junto con otra función en Lambda para guardar esos mensajes en una base de datos.
Capacidad de escritura
Inspeccionando los logs encontré que muchas ejecuciones del lambda ParserPartial fallaban al escribir a la base de datos. Los logs indicaban throttling: “capacidad de escritura excedida”. Fue toda una experiencia (?) leer la documentación sobre capacidades de lectura/escritura y elegir la mejor configuración para mi caso: “On Demand Mode”, dado que mi uso es bajísimo (no habría problema de costos) e impredecible (subo partidos una vez cada taanto).
Tests
Con cada vez más lambdas (de 1 a 3), me sentí inseguro sin unit tests (signos de madurez?).
Agregar tests me obligó a indagar un poco en pytest: cómo mockear librerías externas, variables de entorno y la sentencia with. Contento por haberlo hecho (y por arreglar bugs en el camino!).
Continuará…
Esto sigue siendo una experiencia de aprendizaje, y espero que siga así. Como siempre, todo está en github en caso que sea de interés.
Mis siguientes pasos son arreglar el parser (hay partidos que aún no puedo parsear!), para luego experimentar con las aplicaciones. Hasta pronto!◆