Chessy - Episode 4
This is a fourth edition of my Chessy mini-project, an app to reproduce chess matches. In the previous post, I moved some of the “backend” tasks to the cloud. My approach was super simple and worked well… until I found situations where it doesn’t. This post explains what’s the problem, its solution, and some highlights of the in-between process.
Input too large
I’m processing the PGN files1 using lambda functions. It works well with files from tournament websites, with a decent number of games. An example is the Norway Chess tornament, each file weights ~40KB, around 45 games. But problems arise when I use bigger files, like the ones containing all the games of a player (i.e: Magnus Carlsen’s file weights ~2MB, more than 2000 games).
With big files, the lambda functions fail due timeout. Increasing the timeout work with some files, but the problem reappears with bigger files. I could try optimizing the algorithm, use another language, keep increasing the timeout, etc… but I thought better to cap the work the parser does. Instead of parsing the entire file, parse just a portion.
So I created another lambda function, called Splitter, that reads the entire file (quickly), identifies the games (their beginning and end line), groups them in chunks, and post them in messages to a queue (AWS SQS, one message per group)2. A second lambda function, called ParserPartial, reads those messages and parses just the corresponding part.
Graphically, the backend went from looking like this graph:
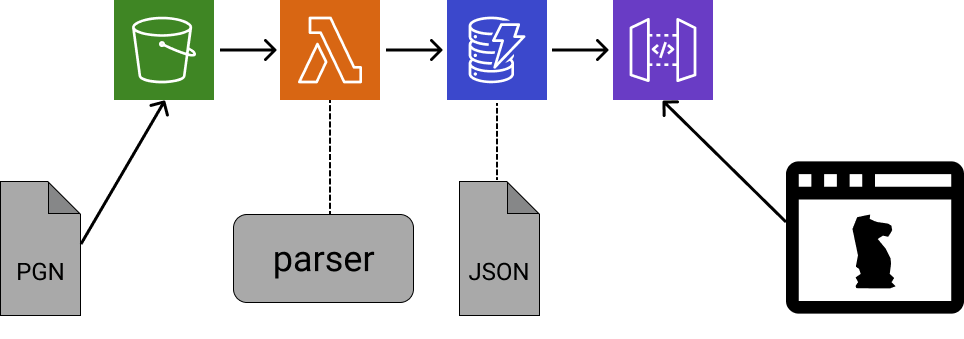
to this one:
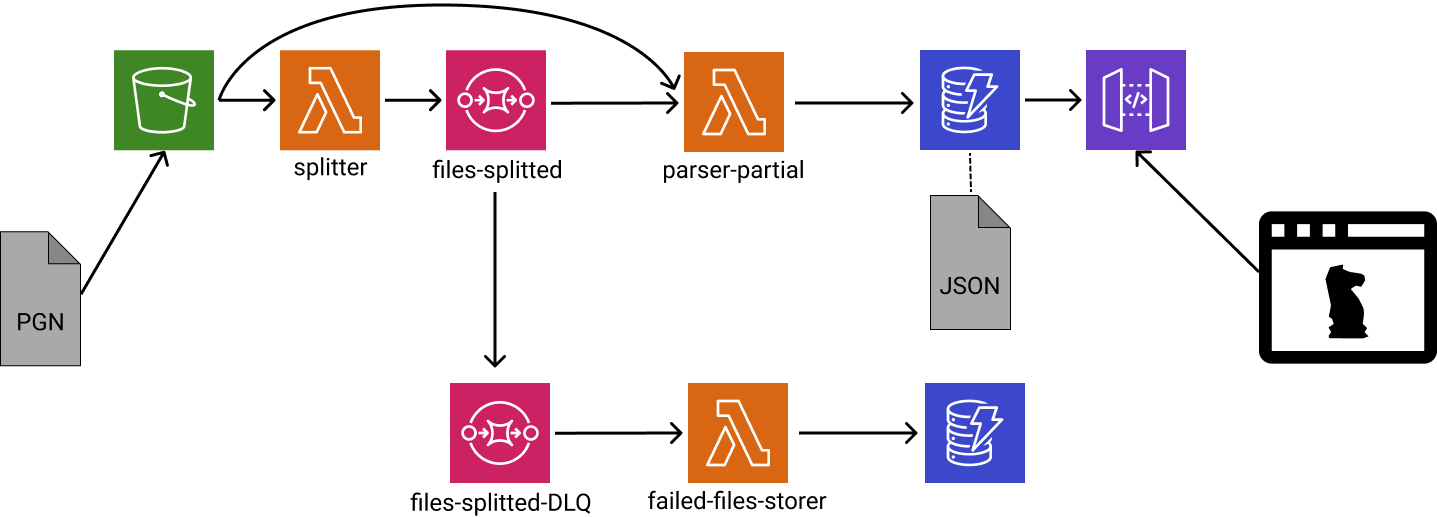
The new schema guarantees a predictable workload in the parser. The bottleneck is not the Parser anymore, but the Splitter. But since its job is relatively simple (much simpler than parsing), I don’t think I’ll see a PGN file too big for it to process…(hahah, now that I said that, I will). But if this becomes a problem, I will use a similar strategy again.
Details
With the main issue solved, other details need some polish: infinite loops, DB Write Capacity and Unit Tests.
Infinite loops
I quickly found that if ParserPartial lambda function fails to process a message from the queue (i.e parsing error), the message enters to the queue again (as it should!). But that triggers another run of the same lambda function, which fails once more, and the message goes back to the queue once again!. This becomes a semi-infinite loop (“semi” because it’s eventually discarded). I am aware this situation is very likely to occur, because my parser cannot process 100% of the games (yet). I will eventually fix the parser, but for that job I need to know which are the problematic games. I’d want to record the troublesome messages instead of discarding them. Fortunately, SQS supports Dead Letter Queue (DLQ), which is another queue for “failed to process” messages. I just had to set this up together with another lambda function to write them in a DB.
DB Capacity
I found that many Lambdas failed with write-to-database errors by looking at the logs. The error messages indicated throttling: “writing capacity limit exceeded”. It was educational to me to dive into the db capacity documentation and determine the best configuration for my use case. I went for “On Demand Mode” because my workload is low (costs won’t impact) and unpredictable (I upload games once in a while).
Unit Tests
With more lambdas than before - three instead of one - I felt unsafe without unit tests (signs of growing up, I suppose?).
Learned more about pytest and and how to mock external libraries, environment variables, and the with statement. I’m happy I added these test… and fixed bugs in the process!
To be continued…
This project is teaching me a lot, and I hope it continues the trend! As usual, everything is hosted in case you want to take a look: github.
My next steps will be about fixing the parser (there’re games I can’t process!), and experiment with the UIs. See you around!◆