Chessy - Parte 3
Tercera entrega sobre el mini-proyecto llamado Chessy, una aplicación para reproducir partidos de ajedrez.
En la primera parte describí la creación de una UI simplona que usa archivos en un formato particular (que lo acababa de inventar). En la segunda parte escribí sobre la generación de tal archivo, creando una utilidad que consta de un lexer, parser y un tablero virtual.
Éste post es sobre mis primeros pasos con AWS S3, DynamoDB, y Lambda, herramientas que usé para procesar y almacenar los partidos.
Pasado
Hasta el día de hoy, el backend podría haber sido representado como en éste diagrama:
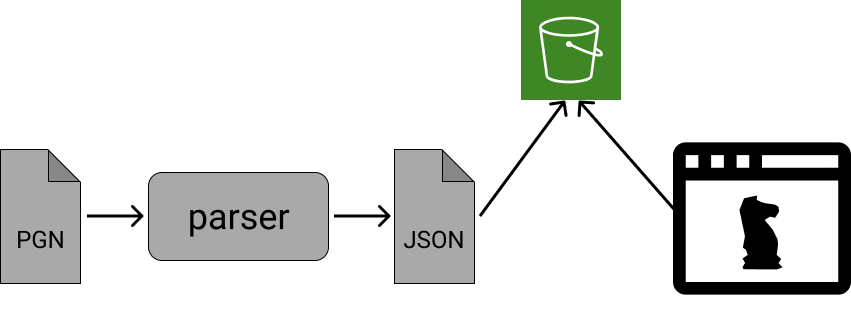
De izquierda a derecha: dado un archivo PGN en la mano (?), lo proceso usando el parser CLI en mi terminal, y al archivo JSON producido lo subo a AWS S3 - manualmente. La UI ahora lo puede reproducir sólo si el id/nombre en la URL está bien escrito.
Está bastante claro que todo es bastante manual, fácil de confundirse, y con una fricción extra para usar la UI. Eso, junto con mis ganas de aprender, hizo que considere algo más automático y basado en “La Nube”.
Presente
A partir de hoy (y hasta algún futuro cercano), puedo dibujar el backend así:
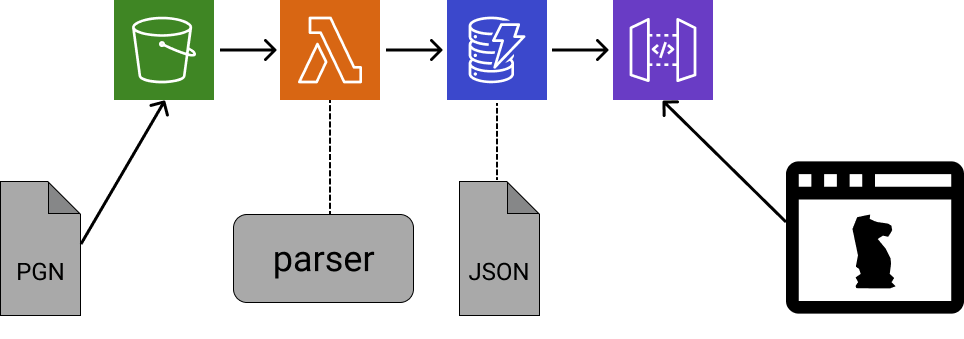
De izquierda a derecha: dado un archivo PGN, lo subo a S3 y… listo! El archivo está disponible para ser visto desde la UI.
Hay un pequeño cloud-setup para que eso suceda: una Lambda function que se auto-ejecuta y procesa el archivo (como si fuera el parser CLI) cuando lo subo a S3; su resultado es almacenado en DynamoDB (base de datos). Agregué dos API endpoints (con API Gateway) que son usados por la UI y acceder la base de datos: uno para obtener una lista de partidos (sólo un par de campos por partido, como el nombre de los jugadores y el resultado), y otro para obtener un partido en particular (con toda la info).
A continuación van algunos detalles técnicos del proceso.
Detalles Técnicos
Creo que toda la experiencia fue buena, como un pequeño workshop en AWS. Tuve que lidiar con IAM, sus roles y sus permisos para cada cosa involucrada (S3 buckets, tablas de DynamoDB, Lambda functions y APIs de API Gateway); es buena práctica dar sólo los permisos mínimos e indispensables (sólo lectura para la mayoría, acceso de escritura a una sóla tabla, restringir el tipo de operaciones…), aunque no siempre es tan simple. Aprendí cosas de Lambda (re diver testearlo NO), su interacción con DynamoDB y lo útil que API Gateway puede llegar a ser.
Sin entrar en demasiados detalles, les comparto algunas curiosidades y trucos que aprendí en el camino.
Lambda Functions
Como escribí anteriormente, la utilidad que procesa archivos PGNs hace lo siguiente: el entry-point lee los argumentos, abre el archivo, procesa el contenido, y escribe el resultado en uno o varios archivos. En una Lambda function, el proceso sería invocado con información del archivo en S3, lo leería y procesaría el contenido, y guardaría el resultado en la base de datos. Es evidente que lo mejor que puedo hacer es modificar el código para que la parte central esté aislada (el procesamiento del texto) y pueda ser reutilizada en las dos situaciones: en la terminal y en Lambda. De hecho, esto está identificado como una de las primeras cosas a tener en cuanto cuando portamos una utilidad a Lambda.
En una Lambda function uno define el entry point (llamado “handler”) que se ejecuta con event y context como parámetros. Esta función viene a ser un entry point adicional al procesador principal.
Al márgen: está bueno que automáticamente Lambda reporte todos los logs a CloudWatch; más fácil el debugging después.
Dependencias
A menos que uno haga las cosas como corresponde y automatice el deployment, el código se escribe en el editor online (meh) o se sube en un zip (see!). Las dependencias deben estar incluídas en el zip, ya que uno no puede controlar en qué entorno corre el programa (tampoco uno debería asumirlo…). En mi caso agregué la libreria sly al zip.
Es muy útil tener a mano un script como éste para crear el “zip mínimo” (que tenga lo justo y necesario) rápido. Ese script incluye sólamente sly y los archivos en src. Quedan afuera los tests, docs, y cualquier otra librería del python environment. Dudándolo un poco excluí también las librerías de AWS como boto3 (no se cual es la recomendación con esto).
DynamoDB
El paso siguiente sería almancenar los resultados, y en lugar de generar archivos (como en la terminal), creo filas en la base de datos.
Para esto elegí DynamoDB; como toda base de datos NonSQL, cada fila es un conjunto de pares campo-valor, siendo uno de ellos la Key o ‘id’ (su valor debe ser único). Así que decidí procesar todos los tag-pairs del archivo PGN (lo que está al principio), que se transformaron en campos de la tabla. El hecho de que en éste tipo de bases de datos (NonSQL) no haya que predefinir el “schema” hace que pueda guardar todos los tag-pairs que encuentre; porque aparentemente no hay una standarización muy profunda en cuáles pueden existir. Por ejemplo, encontré campos como WhiteTitle, Opening y Variation solo en algunos archivos.
Al tema de elegir la Key lo resolví medio de casualidad: encontré que 7 de esos tag-pairs sí son obligatorios (Event, Site, etc). Así que los combino a todos y ya. Otra opción hubiese sido un número incremental, pero nah.
API Gateway
Con todos los partidos procesados y guardados, lo que queda es -básicamente- usarlos. Pero no se puede acceder a la base de datos directamente, hay que crear un servicio/endpoint que lo haga por uno.
La recomendación para acceder a un recurso AWS es usar API Gateway. Así que ahí creé dos métodos de una REST API: uno para obtener la lista de partidos disponibles (el id y un par de campos) y otro para obtener un partido en particular (con todos sus campos). La implementación de esos métodos tiene trucos (?). La mayoría de los tutoriales que encontré te guían a crear otra función lambda para acceder a la base de datos, pero después de buscar bastante encontré que uno puede hacer eso mismo SIN tal función intermedia; así que intuyo que esas guías están pasadas de fecha, o realmente es necesario y hay algo que no entiendo (altamente probable).
Así es como resolví la integración entre API Gateway y DynamoDB:
- crear un método POST en una REST API. TIENE que ser POST.
- editar su ‘Integration Request’, elegir ‘AWS Service’ en ‘Integration Type’, y llenar la region, servicio (DynamoDB), role, etc.
- en Action,
Scanpara el método que obtiene la lista yGetItempara el método que trae un partido. -
editar ‘Mapping Templates’ - venía bien hasta acá. Creé un Template de tipo
application/jsonque lo edité así:- Primer método (obtener la lista de partidos -
Scanaction): necesito pasar el nombre de la tabla (obligatorio) y los campos que necesito usandoProjectionExpression. Estaba todo bien hasta que empecé a ver que algo no funcionaba… y era porque hay algunos nombres que NO se pueden usar en la lista deProjectionExpression, como por ejemplo “Result”. No encontré documentación al respecto (chan!) y terminé usando el parámetro salvadorExpressionAttributeNames. El Mapping Template quedó así:
{ "TableName": "chess_games", "ProjectionExpression": "id, Black, White, Event, #r", "ExpressionAttributeNames":{"#r": "Result"} }- Segundo método (obtener un partido en particular -
GetItemaction): necesito pasar el nombre de la tabla (obligatorio) y laKeydel partido en cuestión. Obviamente no me sirve usar una key fija (a menos que quiera obtener siempre el mismo partido), mas bien necesito usar la incluída en el POST request. Después de leer bastante documentación poco amigable, encontré cómo leer elgameIdprovisto en el request, y el Mapping Template quedó:
{ "TableName": "chess_games", "Key": { "id":{"S": "$input.path('$.gameId')"}} } - Primer método (obtener la lista de partidos -
Humildemente concluyo que a la documentación le faltan un golpe de horno para que sea amigable y clara, especialmente para newbies como uno. Encontré poquísimos tutoriales para cosas básicas, además. Claro, si uno se dedica a ésto profesionalmente, los trucos se aprenden y todo es sonrisas (o no). Quizás sea por estas cosas que productos como vercel serverless functions o netlify functions, que son wrappers para varios servicios, sean mas populares para side-projects.
UI (web)
También actualizé la web-ui y ahora muestra una lista de partidos para seleccionar y reproducir.
En un principio pensé en obtener todos los partidos de una (con toda la info, incluído los movimientos), pero noté que eso implica transmitir bastante información (gracias Developer Tools!) - incluso para una cantidad de partidos bastante humilde como la que tengo ahora. Usando los dos endpoints y obteniendo primero una lista y después el partido en sí, transmito al menos 20 veces menos de información.
La segunda versión de la web-ui se puede ver en este link.
Voy cerrando el post acá. Hay más cosas que quiero probar, mejorar, aprender… cuanto más lo pienso más ideas se me ocurren (buena tiger!). Espero escribirlas pronto!◆