Chessy - Episode 3
This is the third post about the mini-project called Chessy, an app to reproduce chess matches. In the first of the previous two posts I went through the creation of a simple web-ui that replays a chess game stored as a custom-format file in s3. In the second post I described how such custom-format file is created, coding a utility made up of a lexer, a parser and a board.
This post is about my learning and usage of AWS S3, DynamoDB, and Lambda, to process and store the games.
Past Situation
Up until today, the “backend workflow” could’ve been represented as in the following diagram.
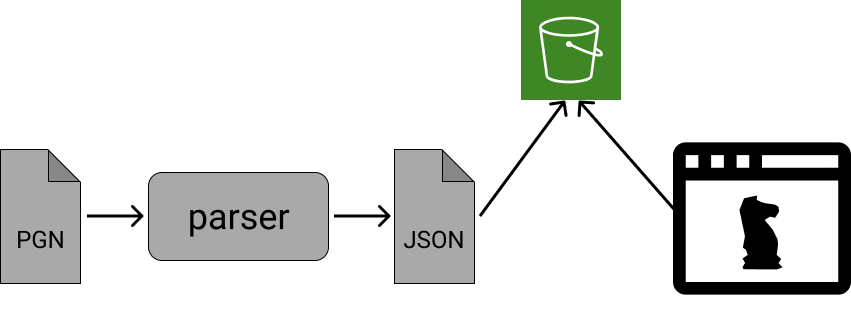
Reading from left to right: having a PGN file, I process using the the parser CLI in my computer, which produces a JSON file that I upload to AWS S3 - manually. The web-ui then reproduces the game specified in the url (needing to match the one in S3).
It’s clear (to me) that this process is very manual, error prone, and imposes some knowledge to use the web-ui. That, and my motivation to learn new things, made me to consider a more automatic and cloud-based redesign.
Present Situation
The workflow today can be drawn as next:
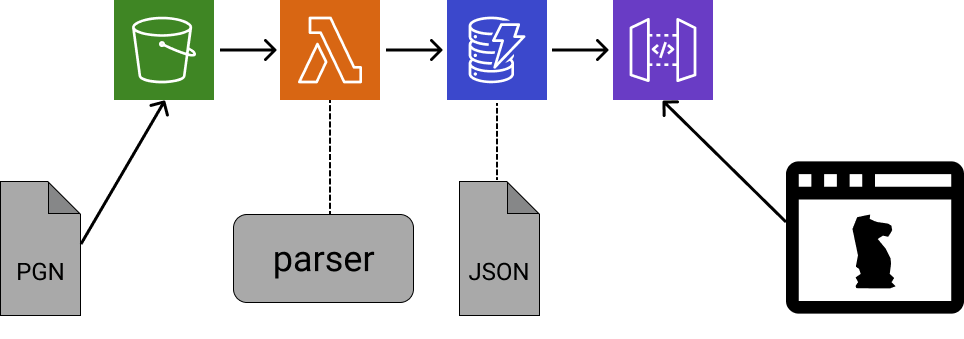
Reading from left to right: having a PGN file, I upload it to S3 and… that’s it! The web-ui will see the available matches and reproduce the one selected.
For that to happen, there is a small cloud setup: I added a Lambda function that will trigger automatically, every time I upload a file to S3, and process the game (as the CLI before). Its results are then stored in DynamoDB (database). I finally added two API endpoints (using API Gateway) the UI can use: one to get the list of games (only a few fields per match, like players and result), and another to get one game (fully, like all its movements).
The rest of the post is about some technicalities involved in this transition.
Technicalities
Overall, this was a good aws hands-on exercise. I dealt with IAM, creating roles and policies for all the components involved (S3 buckets, and DynamoDB tables, Lambda functions and API Gateway APIs); It’s not always trivial to give the most-minimum level of permission over certain objects (like one table or one bucket) and actions (like read-only for the majority). I learned about Lamdbda (having fun testing it (?)) its interaction with DynamoDB, and how useful API Gateway can be.
Without going into a great level of detail, I want to share some curiosities and tricks I learned along the way.
Lambda functions
As I described before, my “PGN parser” is a CLI utility in Python: the entry point reads the arguments, opens the input file, parses its content, and writes the results in files. In a Lambda function, it would be invoked with some S3 file information, would read it and parse its content, and it would write the result in a database. It’s evident that I better refactor the logic to isolate the core part (the parsing of the text) and rehuse it in both use cases: CLI and Lambda. This is among the first things one should care when moving CLI utility to a lambda function.
In a Lambda function, one defines an entry point function (“handler”) that given an event and context performs its work. I therefore wrapped the core functionality in this function, becoming an additional entry point to the core parsing utility.
Side note: it’s nice to see that every log message is sent to CloudWatch, helpful for troubleshooting issues later.
Dependencies
Unless you go serious and setup automatic deployment, the code is written in the online editor (meh) or uploaded as a zip file (yup!), containing the code files. But since you don’t have have control over where the code will execute and how the environment looks like (it’s good to never asume that anyways), all the dependencies should be included as well. For example, I add the sly library to the zip file.
It’s very practical to have a small script like this one to create the “minimal zip”. The script zips only sly and the files in src. Note the exclusion of tests, docs, and many other libraries available in the python environment. I decided to skip the AWS libraries Lambda comes with (like boto3), although I’m unsure if that’s a good practice.
DynamoDB
The next step is to store the results of the parsing. Instead of creating new files, as in the CLI situation, I create new rows in a database.
The database I use is DynamoDB which is NonSQL. Eeach row is a set of fields-value pairs, and one of them is treated as the Key (has to be unique). As I decided to parse all the tag-pairs in the PGN file, they became a fields in the table. The fact that you don’t predefine a rigid schema in NonSQL Databases (opposed to SQL ones) allows me to add any tag pair I find in any game, because apparently they’re not fully standarised: For example, I saw fields like WhiteTitle, Opening, Variation, only in a few of them.
For the Key, I luckily discovered that there are 7 “mandatory” tag pairs, like Event, Site, and Date, and their combination makes it up.
API Gateway
With the chess games processed and stored, it’s time to fetch and use them. However, you can’t access directly to a database over the internet. You need a sort of service/endpoint that queries the database for you.
The recommended way to access AWS resources is through API Gateway, and so here I created two REST API methods: one for getting the list of available games (their ids and a few fields) and another for getting one game in particular (all its fields). Once the API is defined, one should implement the logic with the corresponding AWS resources. It’s interesting that most tutorials out there guide you to create a specific Lambda function to query the database. I assume they are outdated, since after some digging I found that the extra lambda can be avoided.
This is the way I integrated API Gateway and DynamoDB:
- have a POST method in the REST API. It HAS to be POST
- edit the ‘Integration Request’, pick ‘AWS Service’ as Integration Type, and fill/pick the region, service (DynamoDB), role, etc.
- in Action, I wrote
Scanfor the method that gets the list, andGetItemfor the method that gets one game. -
edit ‘Mapping Templates’ - this is the tricky part. I create an
application/jsontype of Template in each method, and edited them in the following way:- for the ‘get list of games’ method (
Scanaction), I provided the table name (mandatory), and the few fields I want using the DynamoDB’sProjectionExpression. The surprise here came when I noticed that you can’t use certain names in theProjectionExpression’s list, even if they are genuine fields in the table. One of them is “Result”. This is poorly documented and dissapointing. I ended up using theExpressionAttributeNamessaviour. The Mapping Template content became:
{ "TableName": "chess_games", "ProjectionExpression": "id, Black, White, Event, #r", "ExpressionAttributeNames":{"#r": "Result"} }- for the ‘get one game’ method (
GetItemaction) I provided the table name (mandatory) and theKey(id) of the element I query for. Instead of a fixed query that returns the same game over and over, this query should use theidgiven by the API caller in the POST request. After reading unfriendly documentations, I nailed down how to read thegameIdin the request, and the Mapping Template became:
{ "TableName": "chess_games", "Key": { "id":{"S": "$input.path('$.gameId')"}} } - for the ‘get list of games’ method (
Overall, I think a big part of the aws documentation is unclear and entry-level tutorials are scarse. This might affect the adoption among amateurs like me. Of course, once you dedicate to this professionally, you might have time to learn all the tricks and things probably become smoothier. Perhaps this is why wrappers around these kind of services (vercel serverless functions, netlify functions) are so popular for side-projects.
WebUI
Finally, I updated the web-ui, showing a list of available games that can be selected and reproduced. I use both ‘get-games-list’, and ‘get-one-game’ endpoints for this.
Initially, I thought about fetching all the games at once (with all their info, including their movements), but then I noticed this involves the transmission of a lot of data, even for the small number of games I currently have (thanks Developer Tools!). By querying the simplified list first, and the entire game later (the two APIs I explained above), I transmit about 20x less data over the network.
The second version of chessy web-ui is available in this link.
I will finish the post here. I have more ideas to try, improve, and learn… more ideas the more I think! I hope to write back soon!◆